Deep learning applied to video encoding systems
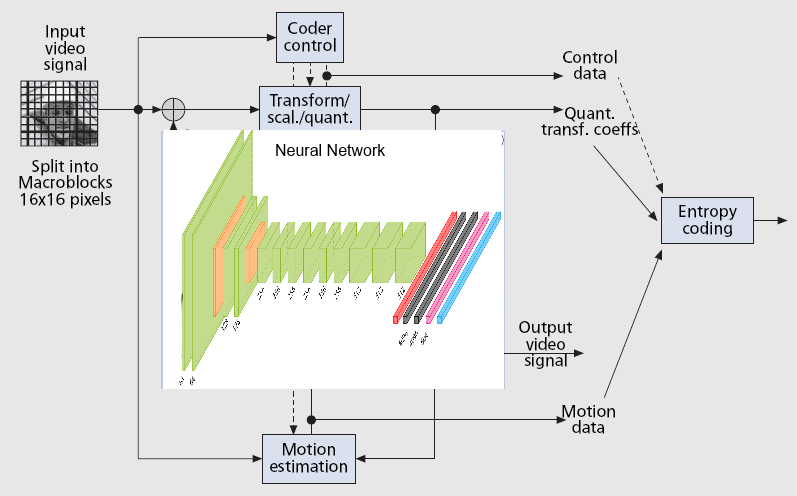
The purpose of this activity based on deep learning is to develop a more efficient compression algorithm than the MPEG HEVC (High Efficiency Video Coding) standard.
Deep learning is a machine learning subset, research field on artificial intelligence, which is trying to obtain abstract representation levels from lower levels features.
The main feature of a subjects called intelligent is its ability to learn and this feature is typical of mathematical paradigms called neural (artificial) networks. Artificial neural networks, mimicking the functioning of biological neural networks, are able to modifiy their behaviour in order to adapt to external inputs.
Simplifying, neural networks are parallel computational models, made by many elaboration units strongly interconnected. The activity of a single node (neurone) is simple and the power of the model is its connections configuration (architectures and weight). Starting from the input units, to which the data of the problem to be solved are provided (pixel of an image), the computation propagates in parallel in the network up to the output units, which provide the result.
Actually they are applied to artificial vision problems, vocal recognition, autonomous vehicles, robots….
In the communication world the techniques to reduce the bit rate have to reduce the redundancies present in the audio video signals by deleting spatial redundancies at the single frame level and temporal between successive frames. The complete informations transmisssion would require a data flow with an extremely high bit rate capacity of the transmission channel. To avoid this problem it is necessary to adopt systems able to compress the source signal.
The purpose of this activity based on deep learning is to develop a more efficien compression algorithm than the MPEG HEVC (High Efficiency Video Coding) standard which requires a preliminary acitvity in order to understand how to choose and optimize the parameters of the network, the same definition of the architecture and the computational complexity.
The Research Centre is dealing with both theoretical analysis of the numerous network architectures (generative, networks with memory, recurrent and convolutional networks) and implementation using technologies such as Tensorflow (released in open source by Google).
Related Projects

Active project
Deep Networks in Content Management Systems
The recent technological advancement of computing systems allows today to find computers with extremely advanced numerical processing capabilities. In particular, the use of Graphics Processing Units (GPUs) for image and multimedia content processing and classification is experiencing a phase of intense development thanks to the deep-seated scientific research conducted in recent years (Deep Learning). Deep Learning is a branch of Machine Learning that uses complex neural networks for a variety of applications. Among these, the application area of automatic classification of audiovisual content is certainly one of the most interesting from the strategic point of view for RAI.