Deep Networks in Content Management Systems
The recent technological advancement of computing systems allows today to find computers with extremely advanced numerical processing capabilities. In particular, the use of Graphics Processing Units (GPUs) for image and multimedia content processing and classification is experiencing a phase of intense development thanks to the deep-seated scientific research conducted in recent years (Deep Learning). Deep Learning is a branch of Machine Learning that uses complex neural networks for a variety of applications. Among these, the application area of automatic classification of audiovisual content is certainly one of the most interesting from the strategic point of view for RAI.
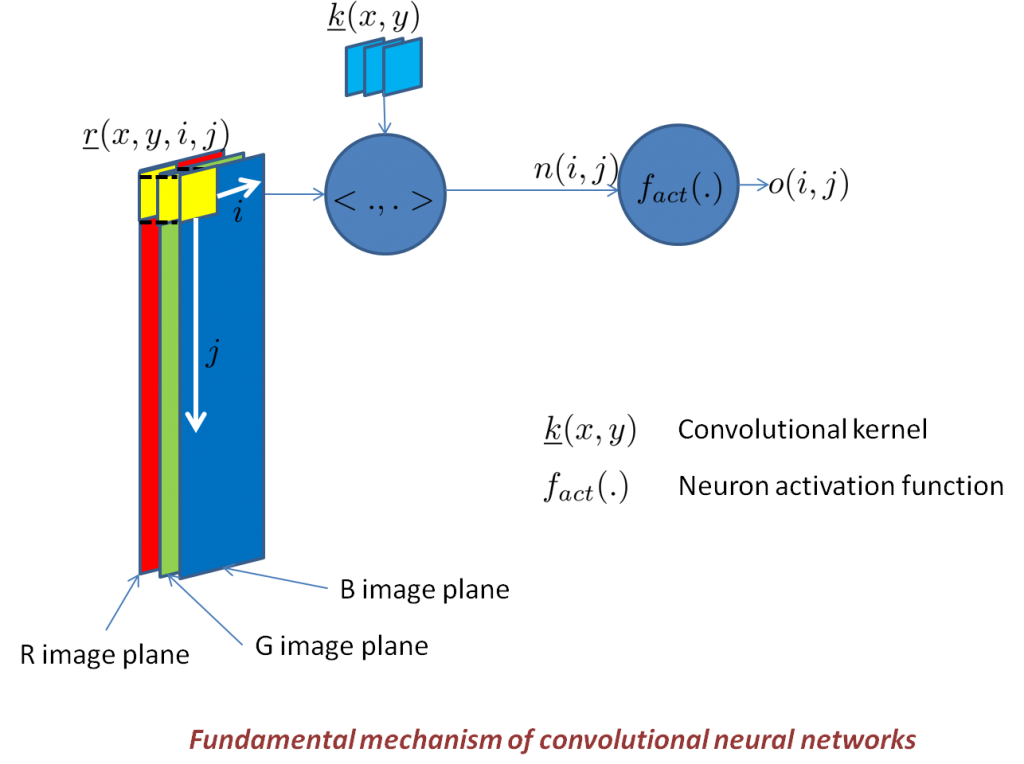
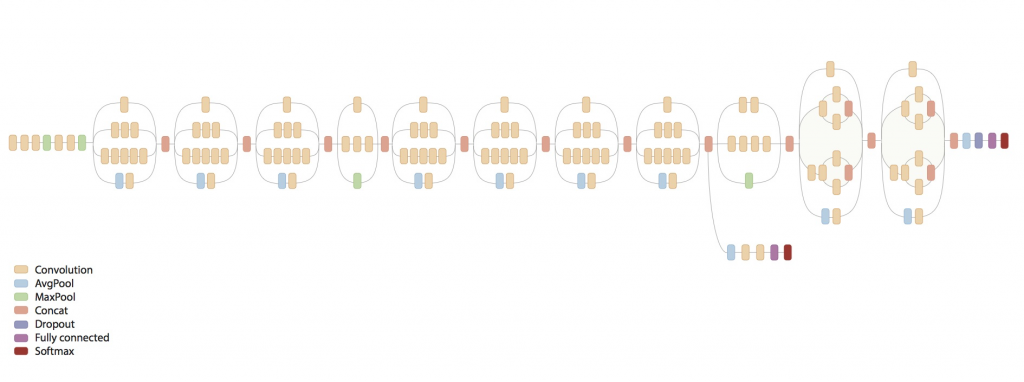
A neural network is a mathematical object inspired by the functioning of the neurological systems of animals. A complex (or deep neural network, from which Deep Learning by extension) is a neural network with many computing layers, much more than traditional neural networks. A computing layer applies simple mathematical operations to its inputs (typically real numbers vectors) that produce new numeric vectors as result , which in turn enter the subsequent layers of the network. There are many types of layers in the scientific literature. In the field of image classification, the layers that have proved to be fundamental, contributing performance that clearly advances the state of the art provided by traditional technologies, are the so-called “convolutional” layers (see figure).
Another distinctive feature of Deep Learning technologies is the nature of their input vectors, that is, the numeric carriers at the entrance of the first layer. Unlike the traditional Machine Learning methods – which normally use numeric vectors that represent some of the content features that are considered important for the specific task – input to complex networks, in the case of image classification, are the images themselves.
In this extremely vivid and continuous context, the project aims to study new deep network methods and architectures that are applicable to the domain of video objects, which today represent a real challenge for these technologies due to their high dimensionality and semantic complexity.
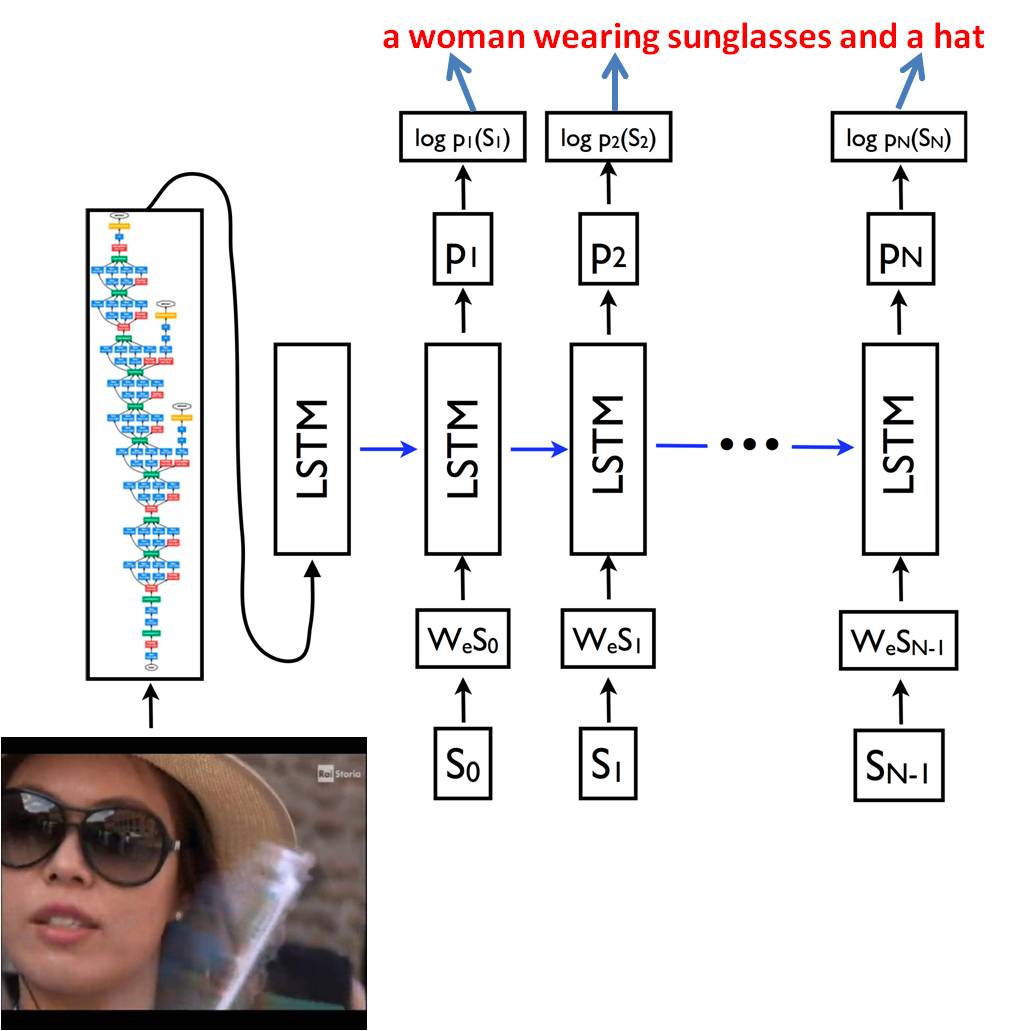
The realization of these architectures would make the RAI archive metadata process more efficient while at the same time increasing the quality and richness of content-related information. The types of information that can be extracted effectively through these networks are not limited to generic classification, although the latter can be achieved principally using an arbitrary classification system (content-oriented, emotional, and recognizing faces of known characters). More articulated versions can extract structured annotations, substantially reducing the gap with traditional documentation systems.
Related Projects

Active project
Technology for "Data Journalism" activities
In the modern digital age, a big challenge lies in the ability of collecting, connecting, analysing and presenting heterogeneous content streams, accessible through different sources, and published through different media modalities. At this purpose, the project is aiming at identifying an end-to-end workflow for data driven journalism.
Active project
Deep learning applied to video encoding systems
The new generation coders are called to face the challenge of providing quality video with an even lower bit rate throgh different algorithmic tools, one of which could be represented by artificial intelligence.